Hochschule Ravensburg-Weingarten University
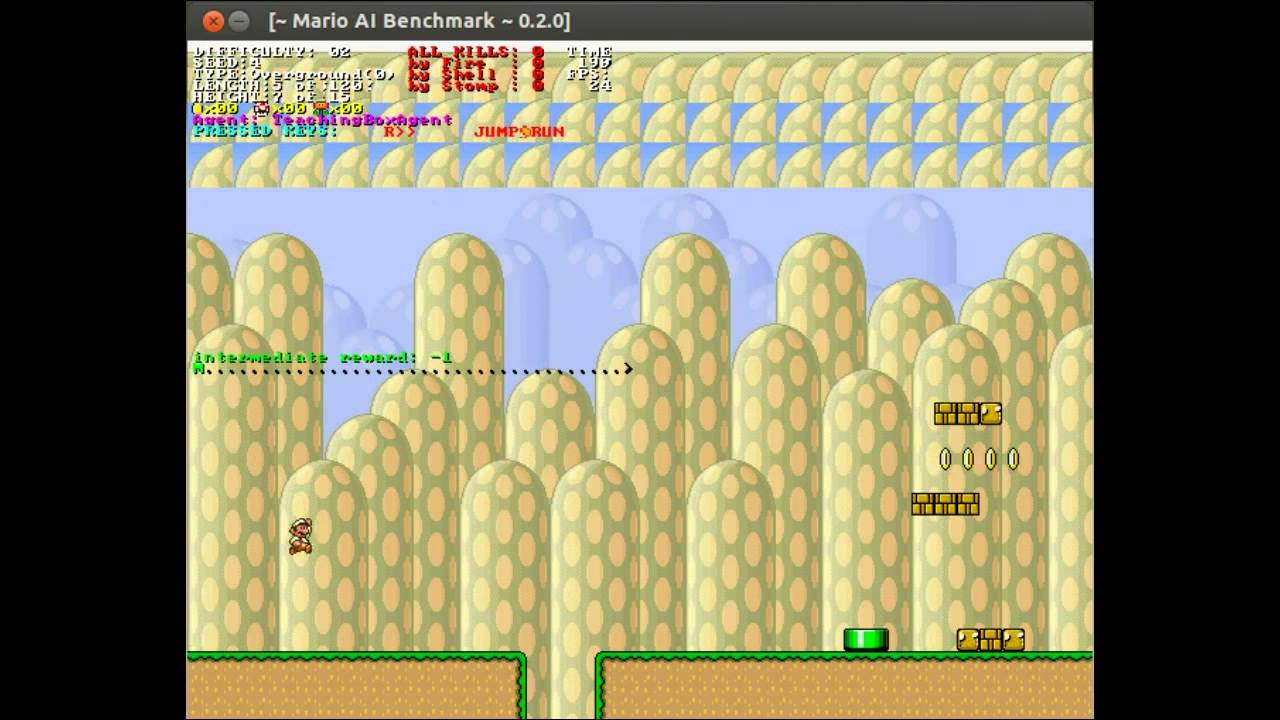
0:00 Start learning using action filters 1+2
2:29 Learning progress / behaviour after 500 episodes
4:29 After 990 episodes (the hopping is gone)
5:18 Using a stronger action filter (1-4) and more enemies
6:22 Patterns are forming
7:18 Successful runs after 20 episodes
This video demonstrates behavior learning through reinforced
sensorimotor interactions in Nintendo’s popular video game “Super
Mario Bros”. The video accompanies a paper written during the
lecture “Applied Neuroinformatics” in WS2013/2014.
Lecturer: Dr. Michel Tokic
Students: Mathias Seeger, Robin Lehmann
Paper Abstract:
We consider the problem of selecting appropriate learning rates and discounting factors in valuefunction-based reinforcement learning. Instead of optimizing those meta parameters by the experimenter, often in a time-consuming manner, we apply randomized meta parameters in multiple instances of the underlying temporal-difference learning algorithm. Hence, learners adapt the action-value function fast or slowly to the temporal-difference error (learning rate), and are far- or near-sighted w.r.t. the future reward (discounting factor). As a consequence the action-selection policy must be based on estimates of multiple action-valuefunctions, for which reason we apply ensemble reinforcement learning algorithms as a feasible solution.
We study the method in the domain of Mario AI having state-action dimensions at large-scale. For tackling the state space of his popular video game platform, we apply some reasonable action-filter heuristics and improve the selection probabilities of remaining actions by using ensemble reinforcement learning. Our results show the effectiveness of this approach.
Source


It's pretty noticeable that once the goombas were added, the number of runs finished with fire flower dropped to almost none. I wonder if this is because a) the computer underestimates the utility of fireflower, b) humans overrate the utility of fireflower, or c) the training give the computer a fireflower at the beginning of the run, so it has no knowledge of Mario's status persisting between runs, and thus places a much lower value on gathering powerups.